
近日,深圳河套学院Al教练平台式样团队,伙同哈尔滨工业大学(深圳)、深圳市大数据征询院、华为磋磨团队,协同深智城AI算力平台,面向国产算力大模子教练开展伙同攻关。依托昇腾910C国产AI算力集群,完成1.6万亿参数大模子DeepSeek-V4-Pro全参数后教练。
这次履活动群众第三方机构在国产算力平台上完成该级别模子教练的关联探索,积存了进军阐发,也印证了国产AI芯片可相沿寰宇级超大参数模子教练职责。
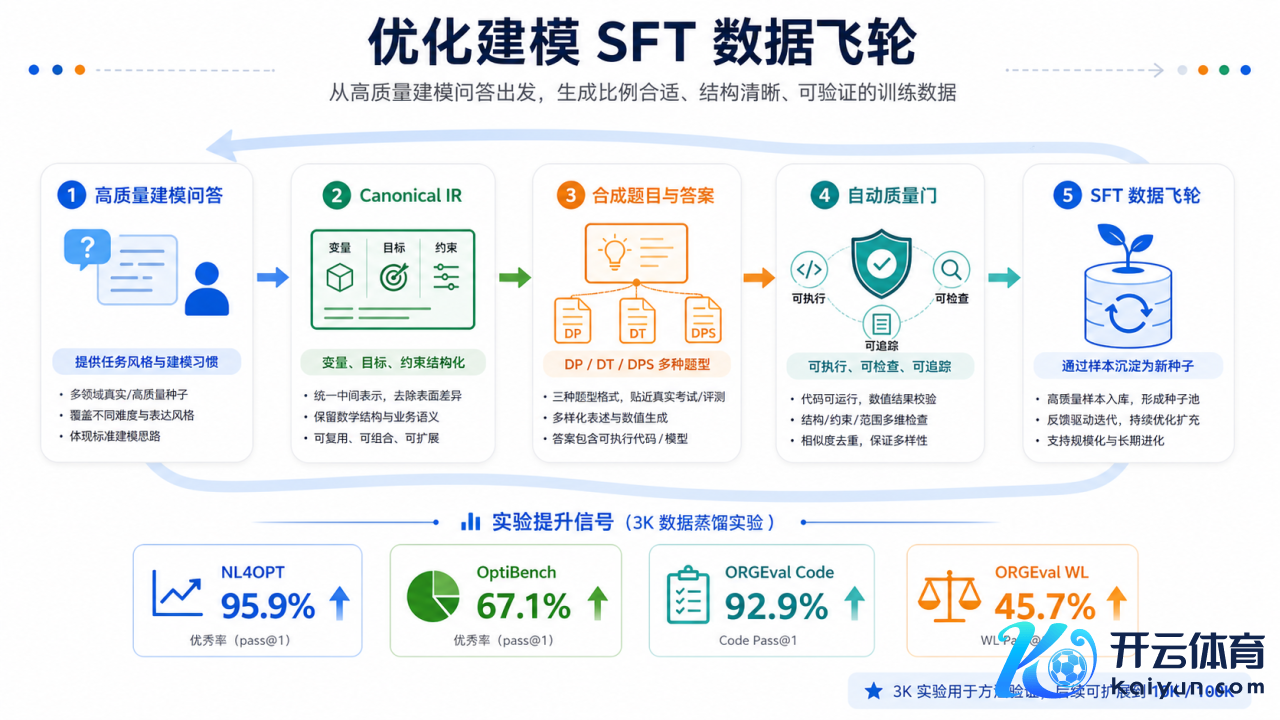
优化建模SFT数据飞轮过程
万亿参数大模子是东谈主工智能规模的主流前沿模子,在逻辑推理、数理策画、代码编写、长文才略会等方面贯通隆起。这类模子的全参数教练,对硬件算力、集群厚实性、算法适配优化均有严苛条目。
始终以来,群众范围内万亿级大模子教练多经受国外高端算力居品,国内国产算力此前主要用于模子推理、小幅微调,难以完周至参数深度教练,这亦然行业发展中多数靠近的技能穷困。
万亿级参数的AI大模子教练难在哪?
如若把教练一个万亿级参数的AI大模子比作解一起超等复杂的数学题,那么每一张策画卡就像别称解题员。他们不仅要单干明确、昼夜无间地连轴转,还不行有东谈主偷懒、不行有东谈主出错,更不行有东谈主掉队。
这次教练的DeepSeek-V4-Pro经受的是羼杂行家模子(MoE)架构,不错把它假想成一个宏大的“行家团”:平时回复问题只激活少数几位行家,看似高效,但后教练时,“行家们”之间的疏浚量却是正常模子的几十倍。再加上动态切换的隆重力机制,这对芯片算力的疗养和显存资源的贬责建议了极其残忍的条目。
浅薄来说,往日的国产算力更多是让大模子“能用”(即推理部署),就像给模子修了一条单行谈,输入一个问题,输出一个谜底。而这次的“全参数后教练”,则是要让模子学会自我反想和调整,颠倒于在单行谈的基础上,又加多了复杂的立交桥和多条反映回路,策画量和通讯量已而翻了好几倍。
三大硬核打破让国产算力“跑得稳”
面对如斯极限的挑战,科研团队在国产AI算力集群上齐全了三大硬核打破:
一是“显存拼图”。万亿级大模子不可能只塞进一张卡,团队遐想了精密的散播式承载决策,把宏大的模子参数像拼图同样,精准地分拨到千卡集群的每一张卡上,算力疗养清表示楚。
二是“负载平衡”。为了幸免MoE模子中有的“行家”忙得够呛、有的却在“闲荡”,团队成心优化了疗养战术,保证了每位“行家”单干合理,跨卡通讯不再“堵车”。
三是“有东谈主‘守夜’”。全参数后教练最怕跑着跑着系统骤然崩溃。本次教练团队搭建了完好意思的监控体系,全部齐全可视可控,确保了长达1500多步的教练过程中,莫得出现一次中断或报错。

式样团队开展技能复盘与学生实战培养
本次探索是国产算力适配超大参数大模子过程中的一次进军进展,有助于普及国内AI产业链自主化水平,缩小行业应用老本,为东谈主工智能技能落地应用提供更多相沿。现在,式样已齐全模子算力期骗率(MFU)进步30%,要道教练算子后果普及14%,各式样的均达到工业级运转时势。
从技能应用角度来看,调用已有模子开展业务推理,与从零完成模子全参数教练分属不同技能法子开云体育,二者在技能难度、硬件条目上存在彰着分离。本次教练截止标明,国产AI算力已可承担顶级大模子教练任务,关联技能旅途具备可行性。